可变分区内存动态分配模拟
可变分区内存动态分配模拟
可变分区是指在进程装入内存时,把可用的内存空间“切出”一个连续的区域分配给进程,以适应进程大小的需要。整个内存分区的大小和分区的个数不是固定不变的,而是根据装入进程的大小动态划分。
可变分区中的数据结构:空闲分区表和空闲分区链。
空闲分区表为每个尚未分配出去的分区设置一个表项,每个表项包括分区的序号,分区大小,分区起始地址。
空闲分区链在每个分区中设置用于控制分区分配的信息以及用于链接各个分区的指针,将内存中的空闲分区链成一个链表。
可变分区中的算法
1)首次适应算法(First Fit)
该算法要求空闲分区以地址递增的次序排序,分配时从表头开始顺序查找,直到找到一个能够满足进程大小的空闲分区为止,然后从进程中切出一块内存空间分配给进程,余下的空间仍然留在内存中。
优点:优先使用低地址的空闲空间,高地址部分很少利用,保证了高地址的留有较大的空闲分区
缺点:低地址部分不断“切割”,使留下许多难以利用的空闲分区,而每次又都从低地址开始,这就会影响查找的速度。
2)下次适应算法(Next Fit)
该算法从首次适应算法演变过来,为了避免低地址小空闲部分分区的不断增加,在给进程分配空间时,不再每次从表头开始,而是从上次找到的空闲分区的下一个空闲分区开始,直到找到一个满足要求的空闲分区,并从中“切出”一块分配给进程。为了实现,要设置起始查询指针,链表的链接采用循环链表。
优点:使内存得到比较均衡的使用,减少了查找的开销
缺点:会使内存缺少大的内存分区,导致大的进程运行不了
3)最佳适应算法(Best Fit)
最佳适应算法就是在剩下的空闲空间中按空闲的大小递增的顺序查找满足条件的最小的空闲分区分配给进程。
优点:第一次找到的空闲分区一定是最优的,系统中也可能保留较大的空闲空间
缺点:链表的表头会留下许多难以利用的小空闲区,而影响分配速度。
4)最坏适应算法(Worst Fit)
最坏适应算法和最佳适应算法正好相反,按大小递减的顺序查找
优点:基本上不会留下小空闲区,不会形成碎片
缺点:大的空闲区被切割,导致较大的进程不能满足,无法运行
下面我主要讲的是首次适应算法和最佳适应算法:
设置空闲分区的数据结构为空闲分区表:
struct Block |
初始化表头的起始地址以及所有空闲分区大小的总和
设置首次适应算法:
void shoucishiyin() |
此算法运行的效果如下:
设置最佳适应算法:
void zuijiashiyin() |
在以上设计算法的过程中,讨论块调出后内存的变化情况是最重要的,只有把全部情况考虑进去之后,才能将最佳适应算法正确的设计出来
下面是我运行的一些结果: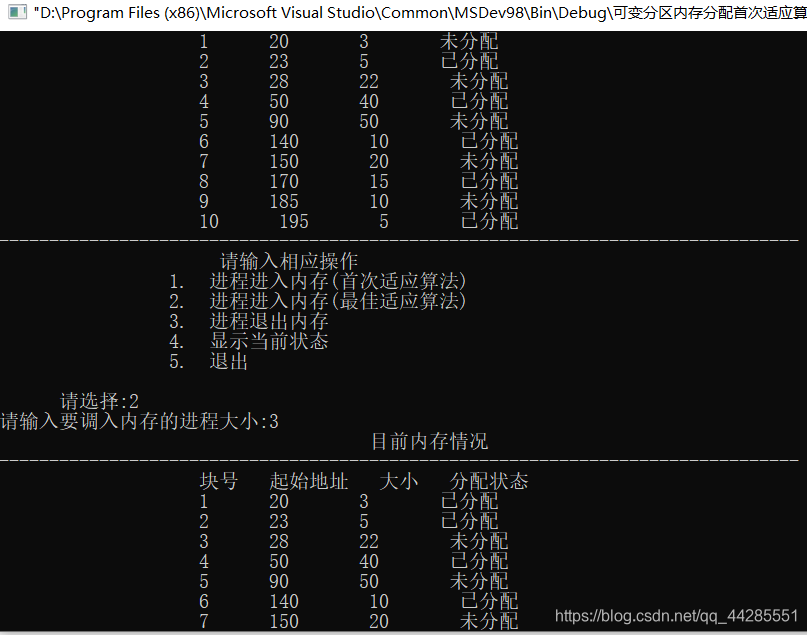
重在理解,代码实现方法有很多种。由于过了一段时间再做改动,就潦草结尾了,对不住各位了。一起加油!!!
 微信
微信 支付宝
支付宝

